State of the Art Language Technologies in Western Armenian
The Armenian Communities Department is delighted to announce that the Western Armenian Universal Dependencies Treebank was released on 15 May 2021, and is now available on the Universal Dependencies Consortium webpage.
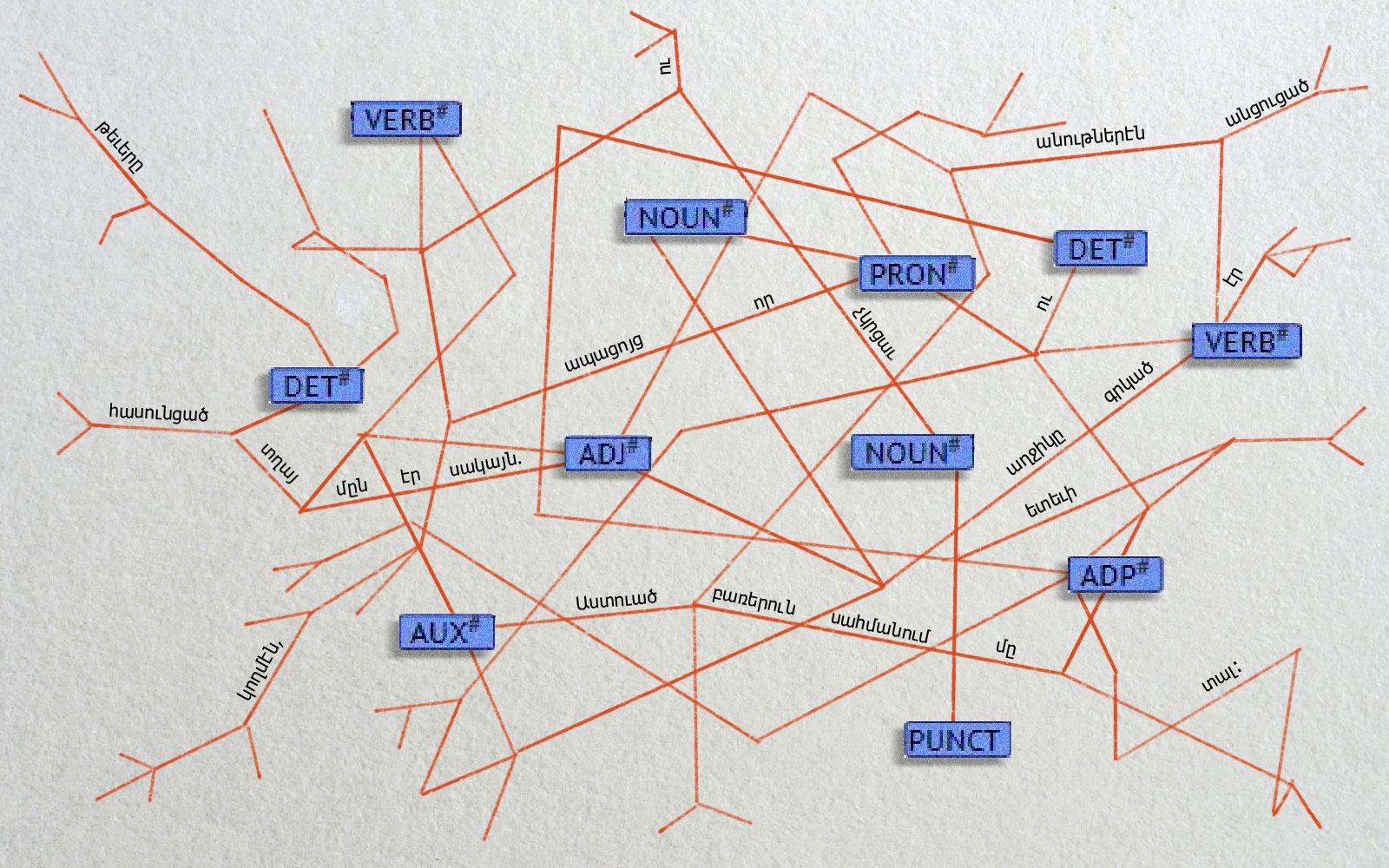
A Treebank is essential for the vitality of any language. It is a linguistic tool that analyzes and describes the structure of the language, identifying its different components in a manner that computer programmes could work with it. Through treebanks, language-related programmes could identify, for example, what is the verb in the sentence, what is the noun, the adverb, the question mark, and so forth, based on which practical applications can be developed. In technical terms, it is a database of sentences which are annotated with syntactic information. Treebanks revolutionized computational linguistics in the early 1990s, after the expansion of machine learning methods and artificial neural networks in the field of Natural Language Processing.
Treebanks play a crucial role in the development of modern language processing systems such as machine translation, part-of-speech taggers, parsers, semantic analyzers and so forth. “Put simply,” explained Razmik Panossian, the Director of the Department, “for a language to be translatable through online tools, to have its own spellchecker and grammar programmes, and to have the means for artificial intelligence processing in that language, it needs its own Treebank. We are particularly pleased that the Foundation played a central role in making the Western Armenian Treebank available to all those who wish to work at the intersection of language and technology.”
Universal Dependencies is a project that develops a cross-linguistically consistent Treebank annotation for many languages, now including both Eastern and Western Armenian. It provides a universal inventory of categories and guidelines to aid with a consistent annotation of similar constructions across languages, while allowing language-specific extensions when necessary.
The new Treebank is based on the Western Armenian section of the Armenian Dependency Treebank, developed by the ArmTDP team led by Marat M. Yavrumyan (Yerevan State University) and Hrant H. Khachatrian (YerevaNN research lab). The Western Armenian Treebank is one of the 202 Treebanks available in 114 languages. It was created completely manually, and thus can be used as gold-standard Treebank data in most Natural Language Processing tasks for Western Armenian. By the end of 2021, the second expanded version of the Treebank will be released.
The Western Armenian Treebank currently consists of 1780 sentences, containing 7.5 million words, compiled from 110 works by more than 50 authors from 1895 to 2010, in many genres such as fiction, personal and official correspondences, travelogues, political and literary speeches, memoirs and travel notes. It is based on the corpus of American University of Armenia’s Digital Library of Armenian Literature (Digilib).
The Western Armenian Treebank, and the Natural Language Processing solutions developed on its basis, are decisive in bringing state of the art language technologies to Armenian, ensuring the vitality of the language in the modern digital era.
Read this article in Armenian
Armenian